


































System bazujący na sztucznej inteligencji nauczył się gry w Go, najtrudniejszej na świecie gry logicznej, bez pomocy ludzi. Po kilku tygodniach nauki pokonywał on wszystkie dotychczasowe wersje programu, w tym te, które wygrywały z mistrzami takimi jak Lee Sedol oraz Ke Jie.
Historia rozwoju AlphaGo – oprogramowania do gry w Go – sięga kilku lat wstecz. Pierwsza wersja oprogramowania powstała w 2014 roku, natomiast dwa lata później AlphaGo pokonało Lee Sedola, arcymistrza z Korei Południowej (w pojedynku tym Sedol wygrał tylko jedną rundę). W tym roku w maju AlphaGo pokonało z kolei trzy do zera chińskiego arcymistrza Ke Jie.

Nowy sukces zespołu z DeepMind, firmy rozwijającej omawiane oprogramowanie, jest nawet większy, bowiem nowa wersja sztucznej inteligencji znacznie przewyższ wszystkie dotychczas stworzone. Informacje na ten temat przedstawiciele DeepMind opublikowali na swoim blogu oraz w czasopiśmie Nature.
AlphaGo Zero
O ile AlphaGo uczyło się strategii gry w Go na podstawie tysięcy potyczek rozegranych przez ludzi, o tyle AlphaGo Zero uczyło się grać samo. Rozpoczynało ono od losowych posunięć, stopniowo doskonaląc umiejętności na bazie uczącej się sieci neuronowej. Po trzech dniach tego procesu AlphaGo Zero wygrało z wynikiem 100 do 0 z wersją programu, która pokonała Lee Sedola. Natomiast po dalszych 18 dniach uczenia się AlphaGo Zero pokonało wersję programu określaną jako „mistrz”, która wygrała m.in. Ke Jie.
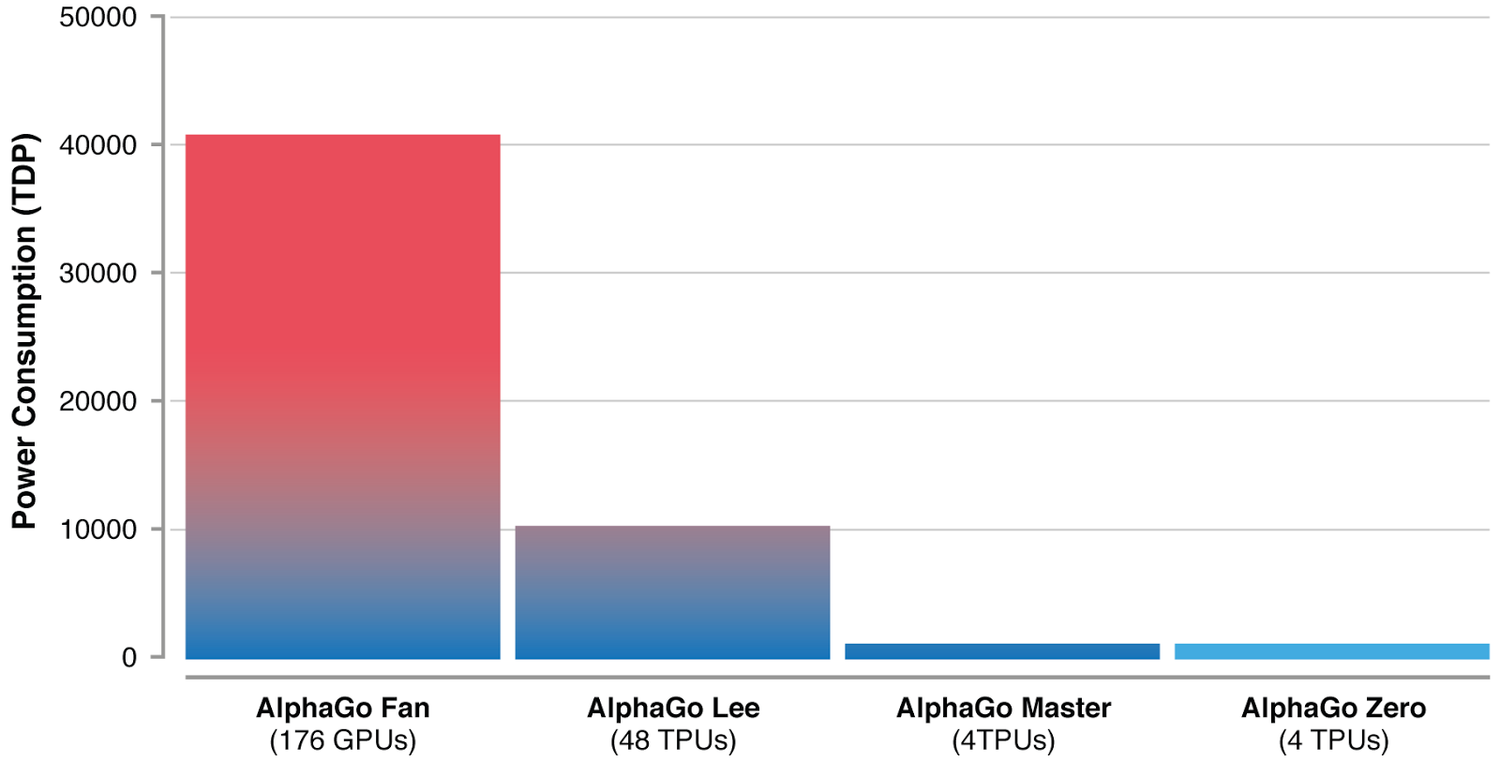
Po 40 dniach od rozpoczęcia nauki oprogramowanie przewyższyło pod względem umiejętności (a dokładniej: wyników rozgrywek) wszystkie dotychczasowe wersje AlphaGo, stając się najsilniejszym systemem zarówno w odniesieniu do tych wirtualnych, jak też mistrzów dyscypliny Go.
Uczenie przez wzmacnianie
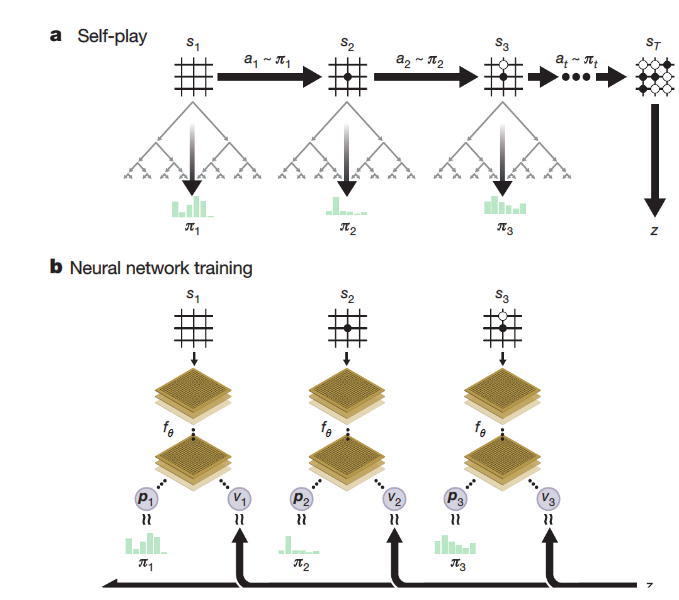
W przypadku AlphaGo Zero bazowano na procesie uczenia się przez wzmacnianie (reinforcement learning). W tym przypadku początkowo system (sieć neuronowa) nie zna strategii gry w Go. Co każdy rozegrany ze sobą pojedynek sieć zmienia się, uczy przewidywania kolejnych ruchów, aż w końcu zaczyna wygrywać – piszą na blogu przedstawiciele DeepMind. O ile więc AlphaGo był tak skuteczny, ponieważ korzystał „z dorobku” poprzednich mistrzów i mógł przewidzieć szanse na wygraną odpowiednio dostosowując strategię gry, o tyle AlphaGo Zero nauczył się grać w Go bez dodatkowych instrukcji i udziału ludzi.
Sieć neuronowa jest połączona z algorytmem wyszukiwania, dzięki czemu przy każdej iteracji tworzone są nowe wersje AlphaGo Zero. Wyuczenie się strategii, mówiąc najkrócej, wynikało z ewolucji na bazie rozegrania milionów gier przeciwko sobie.
Nowy algorytm różni się od poprzednich wersji AlphaGo m.in. tym, że:
- AlphaGo Zero jako informację wejściową wykorzystuje tylko położenie białych i czarnych kamieni na planszy Go; wcześniejsze wersje AlphaGo miały pewną liczbę dodatkowych, „ręcznie zaprojektowanych” funkcji;
- AlphaGo Zero używa jednej sieci neuronowej zamiast dwóch; poprzednio stosowana była „sieć zasad” (policy network) decydująca o kolejnym ruchu oraz „sieć wartości” (value network) określająca możliwego zwycięzcę gry w każdej pozycji;
- AlphaGo Zero nie używa „rolloutów” – szybkich, losowych gier wykorzystywanych przez inne programy do gry w Go, których celem było określenie, który gracz wygra z danej pozycji; zamiast tego oceny pozycji bazuje na sieciach neuronowych.
 Szczegóły dotyczące AlphaGo Zero zostały opublikowane w Nature. Prof Satinder Singh z Michigan University, który recenzował publikację, stwierdza: „Stworzona sztuczna inteligencja znacznie wyprzedza i tak już nadludzką AlphaGo i, moim zdaniem, jest to jeden z największych postępów w dziedzinie uczenia się przez przez wzmacnianie”
Szczegóły dotyczące AlphaGo Zero zostały opublikowane w Nature. Prof Satinder Singh z Michigan University, który recenzował publikację, stwierdza: „Stworzona sztuczna inteligencja znacznie wyprzedza i tak już nadludzką AlphaGo i, moim zdaniem, jest to jeden z największych postępów w dziedzinie uczenia się przez przez wzmacnianie”
Dlaczego przełom?
W przypadku AlphaGo Zero ciągle nie mówimy o sztucznej inteligencji ogólnej, aczkolwiek omawiane wydarzenia istotnie nas do niej przybliżają. Stworzono i sprawdzono w praktyce możliwości technologiczne, które umożliwiają algorytmowi uczenie się od zera, bez pomocy ludzi.
„Jeżeli udało się nam osiągnąć uczenie „tabula rasa”, gdzie oprogramowanie uczy się od zera, to możemy je zastosować również w innych domenach. Opracowany algorytm, po usunięciu specyfiki danej dziedziny, jest ogólny i może być stosowany w wielu nowych dziedzinach” – mówią twórcy AlphaGo Zero
„Podobne techniki można zastosować do rozwiązywania innych złożonych problemów, takich jak np. proces zwijania białek, możliwości zmniejszania zużycia energii czy też opracowywania nowych, rewolucyjnych materiałów” – stwierdza Demis Hassabis, współzałożyciel i prezes DeepMind (na zdjęciu). Firma DeepMind już rozpoczęła wykorzystywanie AlphaGo Zero do badania procesu zwijania białek. Nieprawidłowości w tych procesach uznawane są za powody występowania wielu chorób, w tym Alzheimera, Parkinsona czy mukowiscydozy. Badacze planują niebawem opublikować informacje na temat uzyskanych wyników.
Warto również zauważyć, że AlphaGo Zero stworzył również nowe strategie gry i, zdaniem przedstawicieli DeepMind, miał „autentyczne chwile kreatywności”.
„Program nie jest ograniczony ograniczeniami ludzkiej wiedzy – dzięki temu jest tak potężny” – Demis Hassabis
Czy sztuczna inteligencja pokonała człowieka? Dzisiaj jest pewne to, że maszyna w ciągu zaledwie 40 dni przekroczyła umiejętności ludzi wypracowywane przez tysiące lat. I jest to niewątpliwie przełom.
Zobacz więcej
- Wpis na blogu DeepMind
- Przegląd gier AlphaGo
- Artykuł w Nature na temat AlphaGo Zero
- Dodatkowy artykuł w Nature na temat Go








